KG-R1:基于强化学习的高效可转移的智能体知识图谱检索增强生成
Source
code source :https://github.com/Jinyeop3110/KG-R1.
paper source :https://arxiv.org/abs/2509.26383
摘要
知识图谱检索增强生成(KG-RAG)通过将大型语言模型(LLM)与结构化、可验证的知识图谱(KG)相结合,从而减轻模型幻觉问题,并显式呈现其推理过程。然而,许多KG-RAG系统由多个LLM模块(如规划、推理和响应)组成,增加了推理成本,并将推理行为绑定到特定的目标知识图谱上。为此,我们引入了KG-R1,一种基于强化学习(RL)的智能体知识图谱检索增强生成(KGRAG)框架。KG-R1利用一个单智能体与知识图谱进行交互并将知识图谱作为其环境,在每个步骤学习检索,并将检索到的信息合并到KG-R1的推理和生成中。该过程通过端到端的强化学习进行优化。在跨知识图谱问答(KGQA)基准的实验中,证明了方法的有效性和可迁移性:与先前的使用更大的基础模型或微调的模型的多模块工作流方法相比,KG-R1方法使用Qwen-2.5-3B模型,用更少的token取得了更好的准确性。KG-R1支持即插即用,经过训练后,它在其他知识图谱上也能保持很高的准确性,无需再训练。
引言
典型的KG-RAG采用由四个主要子任务组成的模块化工作流:检索、推理、审查、响应
1、检索以查询KG中的事实
2、推理以处理检索到的信息
3、审查以验证逻辑一致性
4、响应以综合最终答案
存在问题:
1、现有的检索增强生成方法计算成本高:
基于提示的方法通过多次和LLM进行交互,不可避免的导致LLM call、时延和使用token不断累积
2、对其他知识图谱或更新后的知识图谱的可迁移性和可泛化性差:
还有一些基于提示和微调的方法在当前知识图谱中得到了较好的调优结果,当迁移到新的知识图谱时,不能保证性能会完整保留。
KG-R1,一种采用端到端多轮强化学习的智能体KG-RAG系统。
KG-R1的体系结构有两个组件:单个轻量模型作为智能体和知识图谱检索服务器(作为环境)。知识图谱检索服务器托管知识图以及一组检索操作。轻量模型智能体迭代地执行推理和生成步骤,然后执行多轮检索操作,每个决策都基于知识图谱检索服务器获取的知识生成,并获取最终答案。
创新点
1、KG-R1框架:引入强化学习使得轻量模型学习到最优的推理策略,使智能体在知识图谱环境中交替进行推理和检索操作得到最终答案。
2、有效的推理过程:KG-R1在使用轻量开源模型和较低的计算成本之下取得了和比较通用模型(如GPT4等)相同甚至更好的效果。
3、即插即用,跨知识图谱可迁移性:经过训练的KG-R 可轻松迁移至各种知识图谱,并保持KG-RAG的良好性能。
KG-R1框架总体概述
KG-R1将KG-RAG转换为与KG接口(KG检索服务器)的多轮交互。
作者优先考虑两个设计原则。
1、设计了一个单代理体系结构,它可以简化部署并实现高效、低成本的推理。
2、构建了一个与模式无关(schema-agnostic)的知识图谱检索服务器,避免引入针对特定知识图谱的假设,从而在不同的知识图谱之间保持良好的可移植性。
问题
什么是KG-RAG?
什么叫与模式无关?
指系统的设计不依赖某一个特定的 schema 细节,不假设“图里一定有某种具体的实体类型/关系名”,因此可以在不同结构的知识图谱之间复用。
KG-R1 Framework
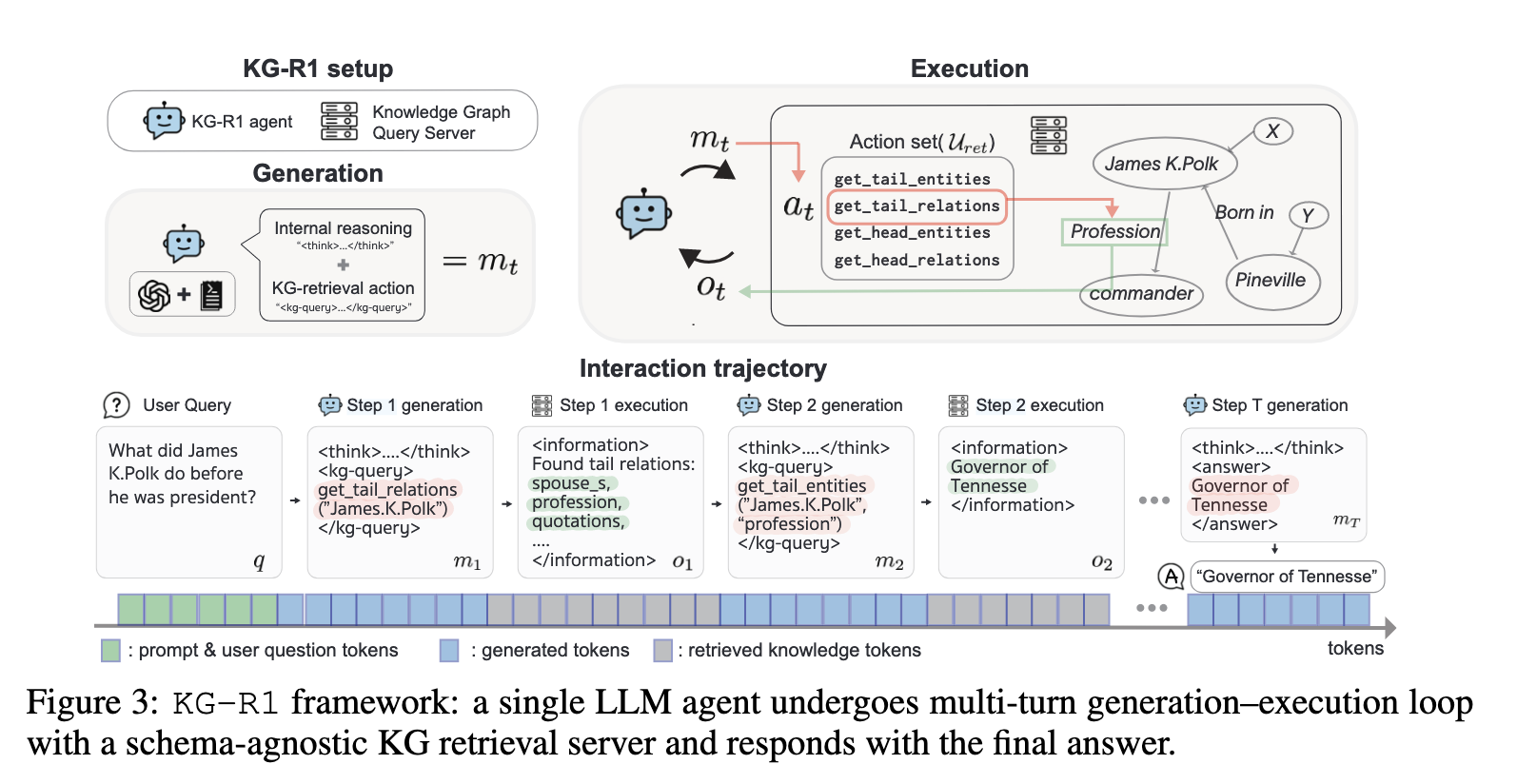
1、知识图谱检索服务
为知识图谱搭建一个后端检索服务,并提供一个单跳检索操作集接口$U_{ret}$,
2、KG-R1智能体
智能体运行包含两个过程,1、生成过程,2、执行过程
生成阶段
包含两个部分响应,一个是思考过程think,一个是检索执行动作 KG Query或者最终答案Answer。
执行阶段:
使用一个精确匹配解析器,解析生成阶段的响应并映射到知识图谱检索服务的操作集上(也可能是响应错误或者预测结果答案),如果解析是答案交互终止,如果是在操作集中,则会生成一个观察结果用于下一轮交互。
提示词如下
1 | You are a helpful assistant. Answer the given question. You can query from knowledge base provided to you to answer the question. You can query knowledge up to [H] times. You must first conduct reasoning inside <think>...</think>. If you need to query knowledge, you can set a query statement between <kg-query>...</kg-query> to query from knowledge base after <think>...</think>. When you have the final answer, you can output the answer inside <answer>...</answer>. |
两个可验证的命题:
检索操作集的完整性:对任意推理路径,通过该操作集的检索动作,都可以得到完整的推理路径。
检索操作无约束可迁移性:对于任何其他的后端知识图谱检索任务,该操作集都可以无缝适用。
KG-R1 Training With RL
通过使用GRPO强化学习算法微调轻量化开源模型找到一个策略,使得KG-R1 智能体学会通过多轮交互有效检索知识图谱上的推理路径并生成精确的答案。
奖励函数:单轮回合奖励 + 全局结果奖励
回合奖励:
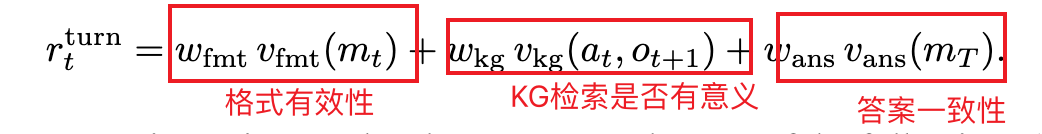
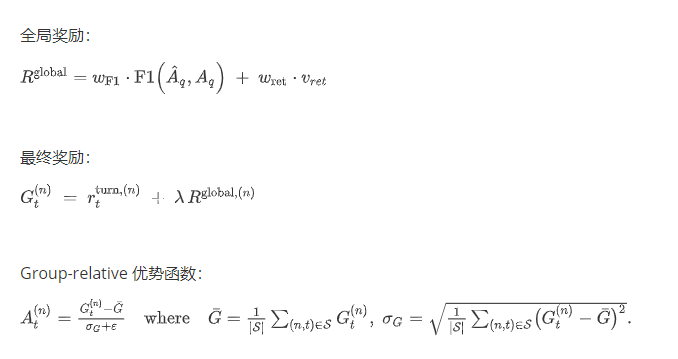
同一批 rollouts 里,谁比平均表现好 → 正优势,差 → 负优势
用 同一个 group 基线,就不需要额外训练一个 value 网络(这就是 GRPO 最大的区别)
把优势分到每一个token:
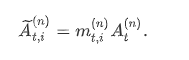
在第 nnn 条轨迹第 ttt 轮的输出文本中,有一连串 token
只对「agent 生成的部分」(不包括系统 prompt、用户 problem)打梯度
然后把同一个 step 的优势分给该 step 的每个有效 token
本质目的:无论增大还是减小概率,每次更新都别太猛。
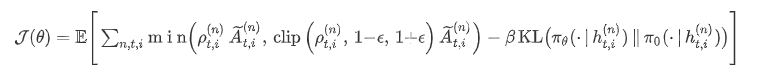
重要性采样比率:
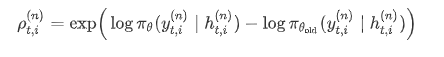
KL散度的作用:限制当前策略要偏离参考策略 (通常是初始模型)太远,防止训练发散。
当当前策略和初始策略的比例相差太多时,即使前面的PPO-clip将策略提高太多时,后面的KL散度也可以按照一定的比例进行惩罚。
在每个 token 上做一个 PPO 式的策略梯度更新
- 用 group-relative turn-level advantage 说“这一整轮行为好不好”;
- 用 ρ 和 clip 控制单步更新强度;
- 用 KL 把策略拉回到原始 SFT 模型附近,保证稳定;最后对所有 rollout 回合 token 求和,得到整体的 RL 目标 J(θ)。
实验部分
1、测试KG-R1在KG训练集上训练后的性能和效率
2、测试KG-R1迁移到不同KG到效果
对比基线:
无 KG 方法: Vanilla LLM, Chain-of-Thought (CoT)。
KG-RAG 方法: RoG (微调 LLaMA2-7B), ToG (GPT-3.5), ReKnoS (GPT-4o-mini) 。
训练数据: 在 WebQSP (Freebase子集) 和 CWQ (Complex WebQuestions, 复杂多跳) 上进行训练 。
对比实验结果
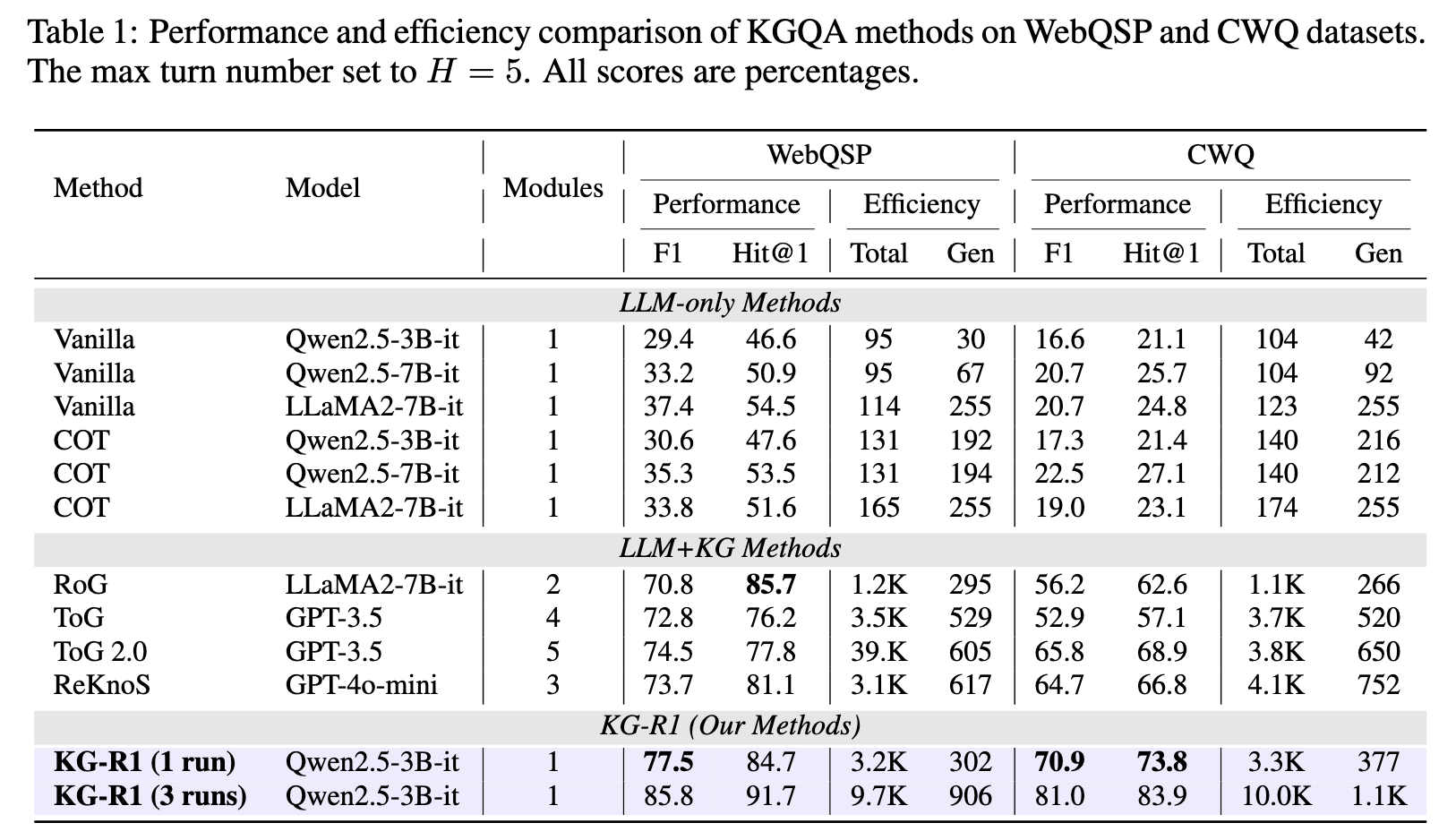
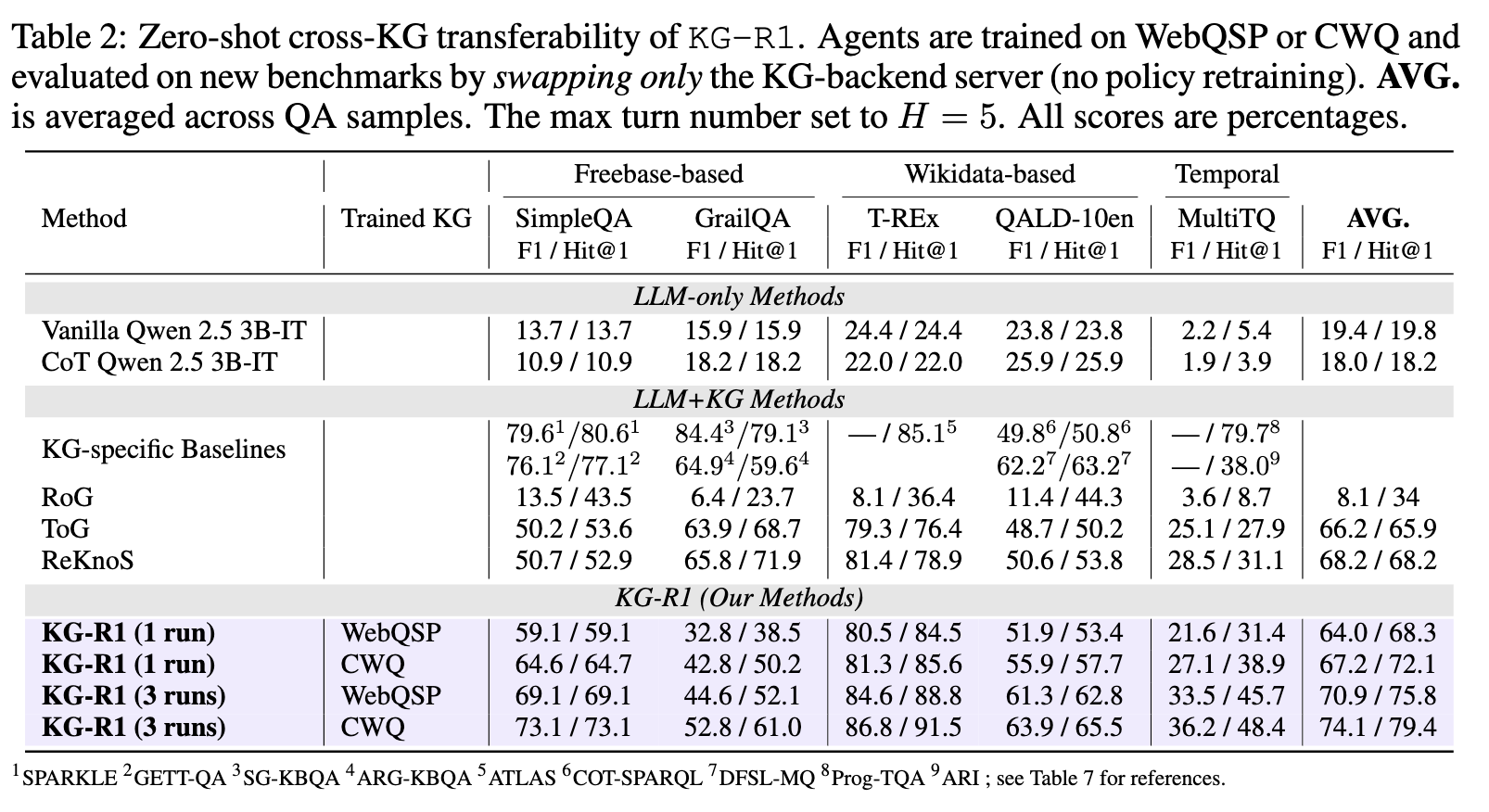
跨图谱迁移实验结果
跨图谱迁移能力
- 直接使用在 WebQSP 或 CWQ 上训练好的 Agent 模型。
- 不进行任何微调,直接更换后端的 KG Server 数据源。
- 在全新的数据集上进行测试。
消融实验结果