You Don’t Need Pre-built Graphs for RAG:Retrieval Augmented Generation with Adaptive Reasoning Structures
论文信息
Title:You Don’t Need Pre-built Graphs for RAG: Retrieval Augmented Generation with Adaptive Reasoning Structures
Source:AAAI 2026
Code:https://github.com/chensyCN/LogicRAG
背景
LLM在处理超出参数知识问题时,常常会产生幻觉,产生事实上不正确的陈述。RAG 通过从语料库中检索查询相关上下文来支持LLM推理,从而解决了这一问题。
但是,传统 RAG 在简单问答中效果不错,但在复杂问答、多跳推理任务中会遇到明显困难:
1、相关信息分散在多个文档中
2、不是一次检索就能拿到完整证据
3、不同证据之间存在逻辑依赖,不能简单拼接
2024年,微软提出了GraphRAG:先把整个语料库构造成图,再在图上进行检索和推理
这种基于图的检索方式在复杂任务中表现出显著的性能。
现有GraphRAG方法的不足
1、离线建图代价高:需要提前处理整个知识库,消耗大量时间和 token。
2、图质量不稳定:自动建图可能引入错误边、冗余连接,影响后续检索。
3、静态图不够灵活:知识库图是预先建好的,但真实问题的推理路径是动态的,静态图未必适配当前问题。
创新点
论文提出了一种逻辑感知的检索增强生成框架(LogicRAG),该框架在推理时动态提取推理结构,无需预先构建图即可指导自适应检索。
1、分析了现有GraphRAG局限性,提出了一种在推理时动态提取推理结构的新框架LogicRAG,用于指导自适应检索。
2、用有向无环图对查询逻辑依赖关系进行建模,提供了一种有原则的、通用的推理结构建模方法。
3、使用拓扑排序将图推理线性化、引入上下文总结摘要和图剪枝来实现高效的推理。(关键机制)
方法论
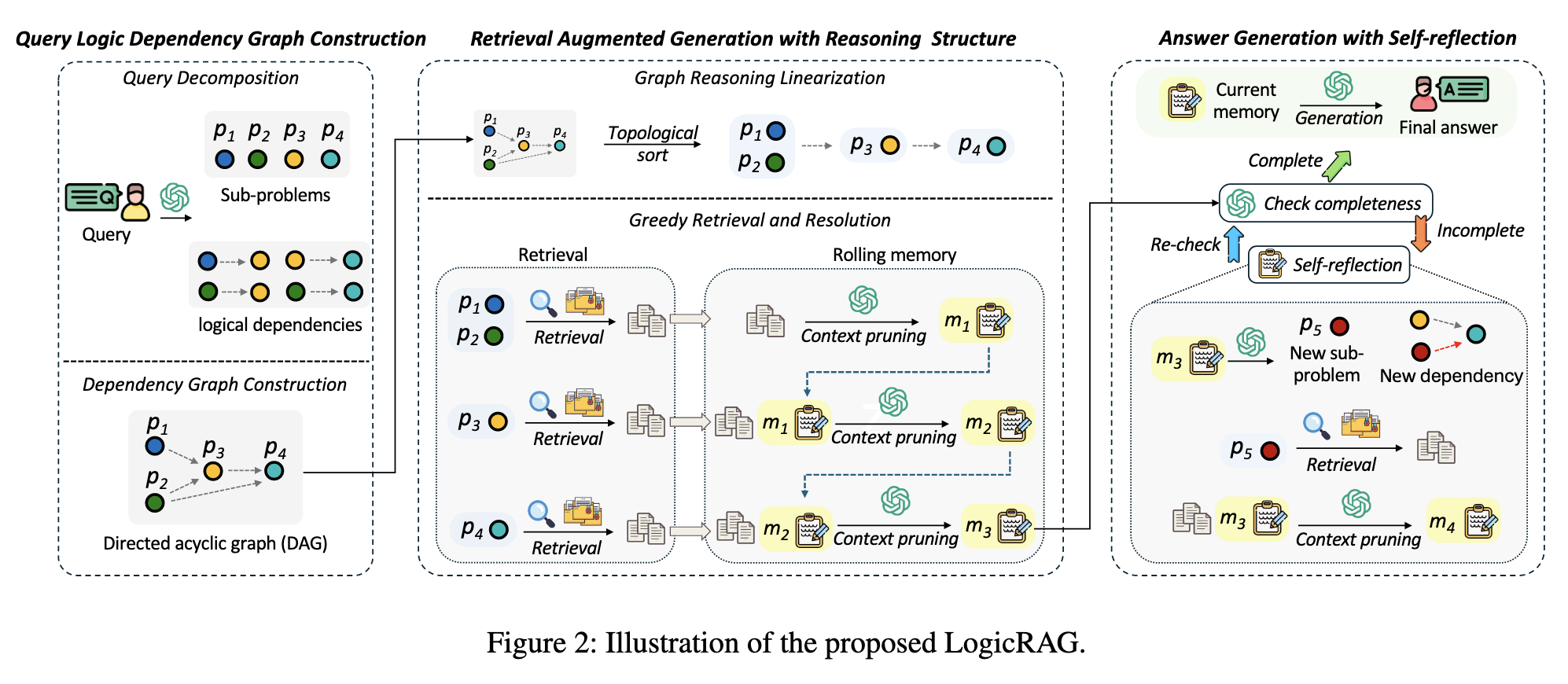
1、问题分解:给定复杂问题 Q,先用 LLM 将其拆成若干子问题
2、构建查询逻辑依赖图:把每个子问题作为图中的一个节点,由 LLM 判断依赖关系,构建一个有向无环图
3、拓扑排序:将图推理线性化,得到一个合理的求解顺序
4、检索与求解:用“当前子问题 + 已有父节点答案”进行检索;根据检索结果回答当前子问题。(上下文摘要总结和图剪枝)
Rolling Memory滚动记忆:Mem(i)=Summarize(Mem(i−1)∪R(p(i)))
取旧记忆,加上当前检索结果,用 LLM 做一次摘要融合,得到新的记忆
图剪枝:同一 拓扑排序 的子问题有时可以合并。合并成统一查询,得到共享上下文再分别解答子问题
5、自我反思与动态扩展:如果系统发现当前图还不够完整、信息还不足,就触发反思,新增子问题,补充依赖边,继续推理
实验分析
1、三个数据集:HotpotQA、2WikiMQA、MuSiQue
2、对比实验结果
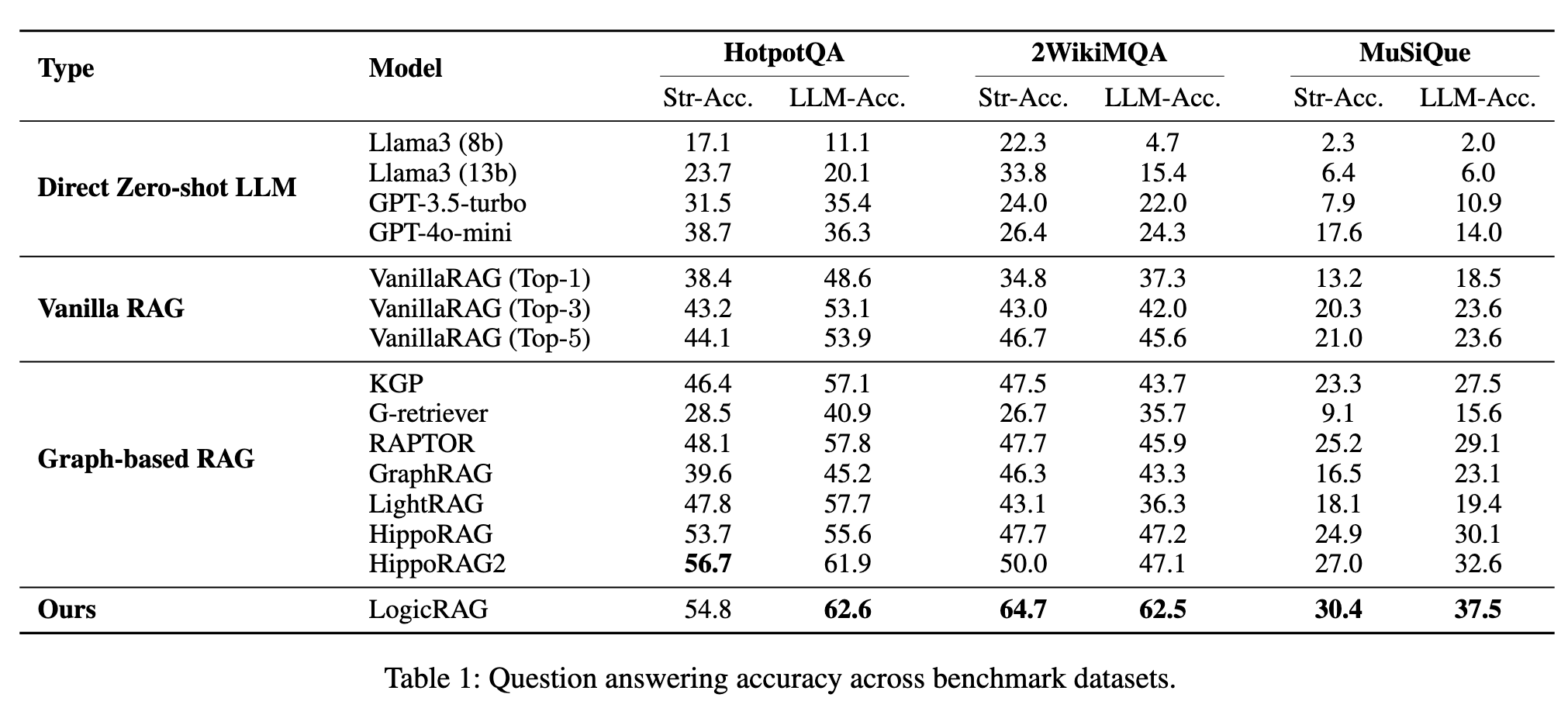
LogicRAG 整体优于 Vanilla RAG,也优于多种 GraphRAG 基线
3、效率与成本分析
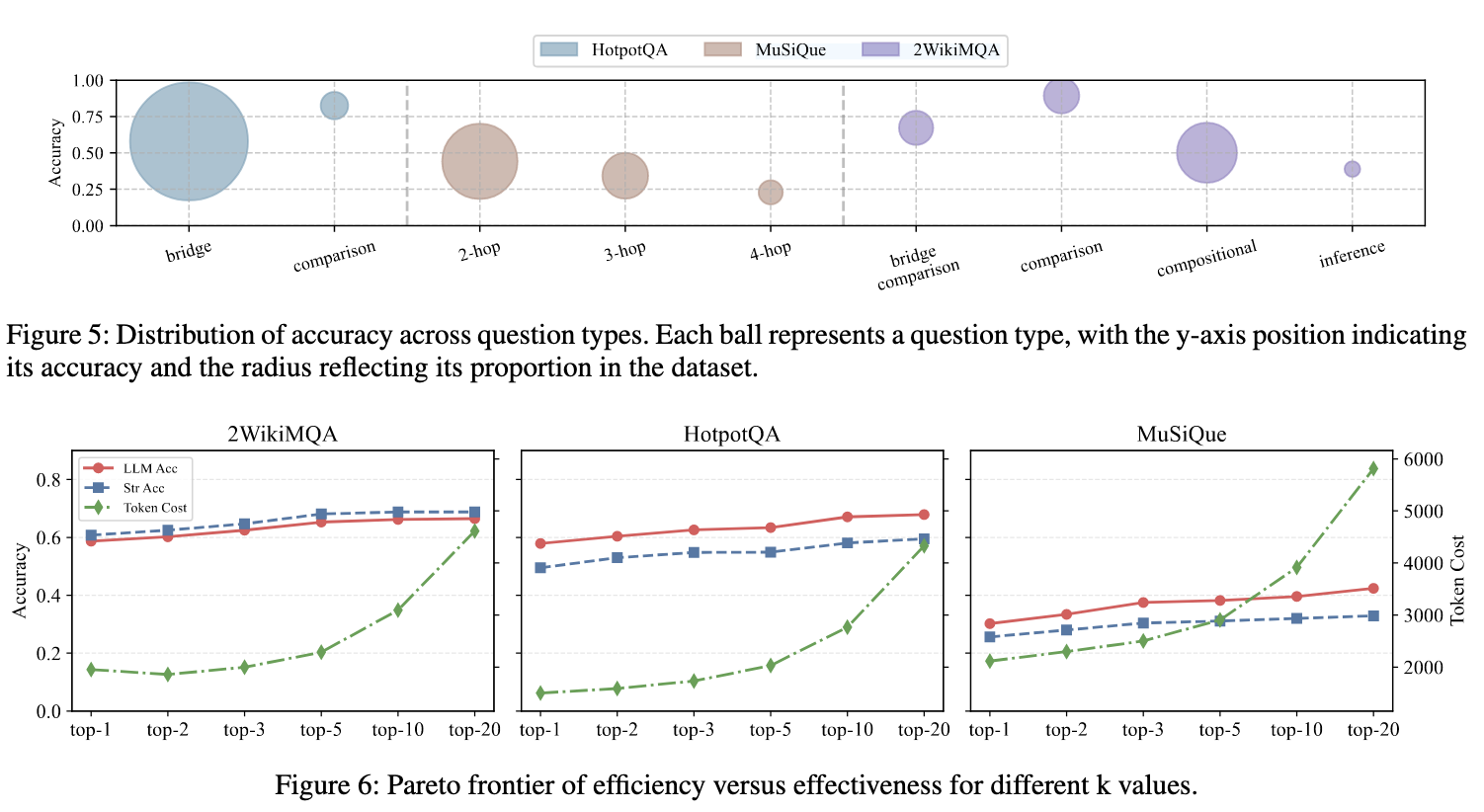
图5:不同类型的问题上的准确率和数据分布结果
图6:top-k 检索 对准确率和token成本的影响
检索更多,效果会提升,但提升效果逐渐变小,token成本也会提升的快
4、时间效率结果
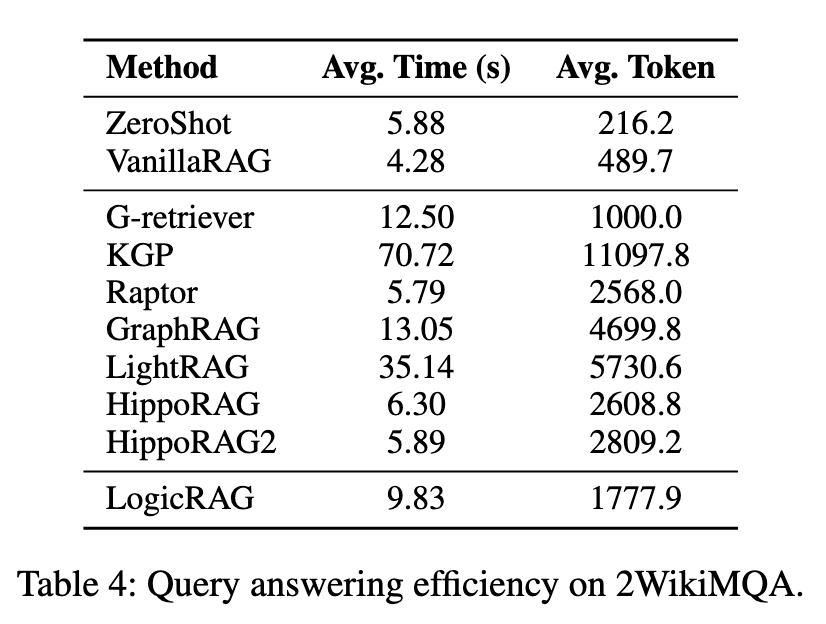
平均时间:9.83 平均token:1777.9
时间不是最优,但是 token 成本控制较好
5、图剪枝的有效性验证
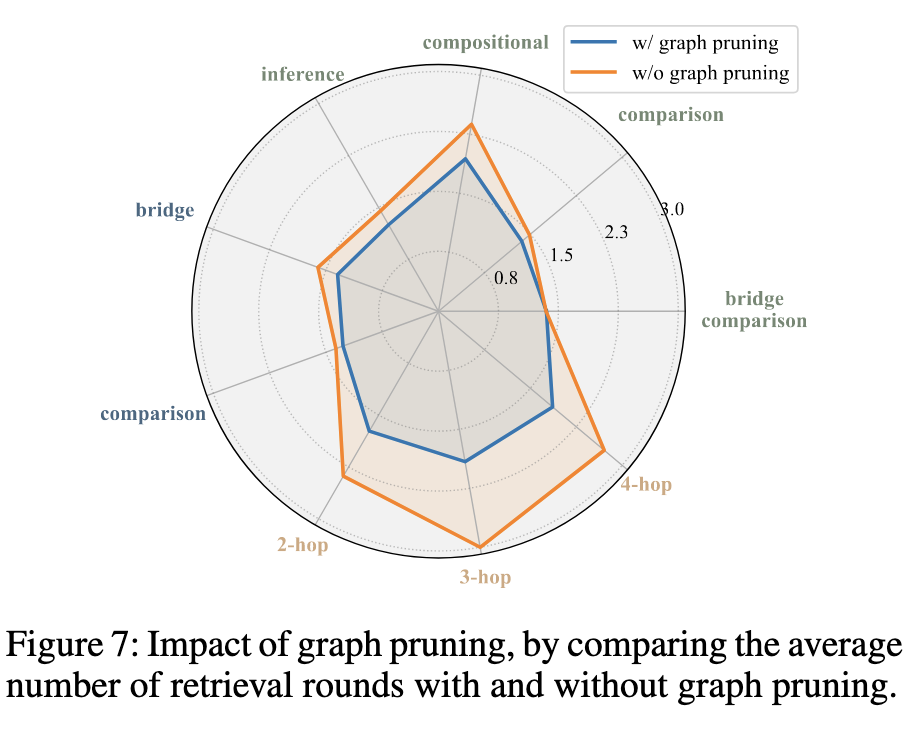
加入 图剪枝 之后,各类问题的平均检索轮数都下降了。说明图剪枝确实减少了冗余子问题带来的重复检索。
总结
LogicRAG 把 GraphRAG 从知识库层面转移到问题推理层面。通过动态构建子问题依赖图,让检索和推理按逻辑顺序展开,同时通过 上下文摘要总结 和 图剪枝 控制成本。相比传统静态 GraphRAG,它更灵活、更贴合复杂问答。